Problem:
Zadanie zostało zdefiniowane przez managera w ten sposób:
- Dane z Databricks mają zostać przesłane na Azure Synapse
- Security utworzyło i otworzyło odpowiednie private endpointy.
- Dostałeś też namiary na service principala, którego wykorzystasz do zapisywania danych z Databricks na Azure Synapse.
Będziesz używał sparka, żeby od razu stworzył tabelę i dane. Będzie to szczególnie pomocne gdyż danych nie jest zbyt dużo. Nie powinno być żadnych problemów wydajnościowych.
Niestety pojawiają się problemy zupełnie innej natury. Przy próbie wstawienia danych dostajesz błąd:
"com.microsoft.sqlserver.jdbc.SQLServerException: The statement failed. Column 'drone_spec_key' has a data type that cannot participate in a columnstore index."Rozwiązanie:
Spark wysyłał do Synapsa create i insert statement w tym samym czasie. Błąd wynikał z tego, że Synapse przy próbie stworzenia tabeli jednocześnie próbuje stworzyć custered index. Niestety ograniczenie, które posiada to brak możliwości stworzenia indeksu na kolumnach, gdzie typ danych zdefiniowany jest jako: VARCHAR(max), NVARCAHR(MAX) a to się dzieje, gdy spark próbuje stworzyć tabelę.
Jako rozwiązanie zastosowano:
- Najpierw została tworzona tabela po stronie Azure Synapse Analytics
- Dopiero później zostały wstawione do niej dane
Szczegóły kodu oraz alternatywne, dające więcej możliwości, rozwiązanie poniżej.
Kod który nie działa
Pokażę najpierw kod, który nie działa żeby wytłumaczyć naturę błędu.
Poniższy kod próbuje stworzyć tabelę przed wstawieniem rekordów. Tabela nie istnieje jeszcze na Azure Synapse i spark próbuje ją utworzyć. Co ważne kolumna drone_spec_key jest typu string. Przechowywane są tak unikalne specyfikacje dronów.
df.write.format('jdbc') \
.option('url', azure_sql_url) \
.option('dbtable', 'next_level_dm.d_drone_spec') \
.option('database', database) \
.option('accessToken', db_access_token) \
.mode('overwrite').save()
com.microsoft.sqlserver.jdbc.SQLServerException: The statement failed. Column 'drone_spec_key' has a data type that cannot participate in a columnstore index.Komunikat błędu mówi wiele o problemach.
Źródła problemów
Spark ze swojej strony wszystkie kolumny, które mają typ danych String przekształca na nvarchar(max) gdy próbuje zapisać do Azure Synapse:
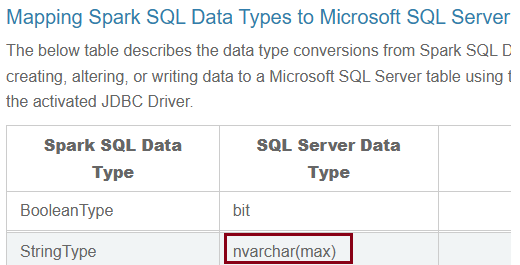
Źródło:
Spark jest naszym pierwszym źródłem problemów. Ale jest jeszcze drugie: Azure Synapse.
Gdy w Azure Synapse próbujesz tworzyć tabelę i nie podajesz indeksów z jakimi dana tabela ma zostać stworzona, wtedy domyślnie tworzone są columnstore indexes. Niestety mają one jedno istotne ograniczenie, które sprawia, że jest to problem w tym przypadku:

Azure Synapse nie pozwala utworzyć indeksu, gdy tabela ma kolumny o typie varchar(max), nvarchar(max) etc..
Nie stworzymy tabeli w Azure Synapse, gdy opieramy się o domyślne typy danych proponowane przez Spark.
Rozwiązania
Rozwiązanie jest więcej niż jedno.
Po pierwsze można najpierw stworzyć tabelę po stronie Azure Synapse a potem już tylko wstawiać do niej dane.
Czasami, może okazać się, że jest to jedyne dostępne dla Ciebie rozwiązanie, bo nie masz uprawnień do tworzenia tabel w Azure Synapse.
To rozwiązanie ma bardzo dużą zaletę, pozwala na precyzyjne określenie typu danych i indeksów, jakie mają być stworzone na tabeli. Wtedy zapisywanie danych do tabeli odbywać się będzie przy użyciu takiego kodu:
df.write.format('jdbc') \
.option('url', azure_sql_url) \
.option('dbtable', 'next_level_dm.d_drone_spec') \
.option('database', database) \
.option('accessToken', db_access_token) \
.option('truncate', 'true') \
.mode('append').save()Zmieniony został tryb ładowania danych z overwrite na append.
Zakładamy, że ładujemy tabelę całościowo i możemy wcześniej zrobić truncate na tabeli. Potem wykonamy tylko append danych do pustej tabeli. Czyli zapiszemy wszystko co jest w data frame.
Jak dla mnie to jest preferowana opcja.
Drugą możliwością jest określenie typów danych dla kolumn w Synapse. Wtedy unikniemy problemów z tworzeniem indeksu dla kolumny nvarchar(max). Dodatkowo, co jest dużą zaletą, z poziomu sparka będzie możliwość definiowana typów danych dla tabeli. Co może być istotną zaletą, w momencie, gdy jest potrzeba rozbudować zapytanie lub zaszła zmiana w typie danych dla kolumny.
Definiowanie typów danych w spark wyglądałoby w ten sposób
df.write.format('jdbc') \
.option('url', azure_sql_url) \
.option('dbtable', 'next_level_dm.d_drone_spec') \
.option('database', database) \
.option('createTableColumnTypes', 'drone_spec_key varchar(50)') \
.option('accessToken', db_access_token) \
.mode('overwrite').save()Zwróć uwagę na linijkę z: createTableColumnTypes, w niej określasz typy danych dla kolumn, które chcesz zmienić. Nie musisz definiować wszystkich kolumn które masz w zapytaniu, tylko te dla których chcesz, żeby był stworzony inny typ danych niż domyślny.
To jest też ciekawa opcja.
Możesz dodać tam jeszcze linijkę:
option('truncate', 'true')Wtedy tabela, gdy już istnieje nie będzie tworzona na nowo, będzie tylko czyszczona przed wstawieniem rekordów.
df.write.format('jdbc') \
.option('url', azure_sql_url) \
.option('dbtable', 'next_level_dm.d_drone_spec') \
.option('database', database) \
.option('createTableColumnTypes', 'drone_spec_key varchar(50)') \
.option('accessToken', db_access_token) \
.option('truncate', 'true') \
.mode('overwrite').save()Daj znać, które rozwiązanie było dla Ciebie bardziej przydatne!